

Authors:
(1) Zengyi Qin, MIT & MyShell.ai and (email: [email protected]);
(2) Wenliang Zhao, Tsinghua University;
(3) Xumin Yu, Tsinghua University;
(4 ) Xin Sun, MyShell.ai;
Table of Links
Abstract
We introduce OpenVoice, a versatile instant voice cloning approach that requires only a short audio clip from the reference speaker to replicate their voice and generate speech in multiple languages. OpenVoice represents a significant advancement in addressing the following open challenges in the field: 1) Flexible Voice Style Control. OpenVoice enables granular control over voice styles, including emotion, accent, rhythm, pauses, and intonation, in addition to replicating the tone color of the reference speaker. The voice styles are not directly copied from and constrained by the style of the reference speaker. Previous approaches lacked the ability to flexibly manipulate voice styles after cloning. 2) Zero-Shot Cross-Lingual Voice Cloning. OpenVoice achieves zero-shot cross-lingual voice cloning for languages not included in the massive-speaker training set. Unlike previous approaches, which typically require extensive massive-speaker multi-lingual (MSML) dataset2 for all languages, OpenVoice can clone voices into a new language without any massive-speaker training data for that language. OpenVoice is also computationally efficient, costing tens of times less than commercially available APIs that offer even inferior performance. To foster further research in the field, we have made the source code3 and trained model publicly accessible. We also provide qualitative results in our demo website4 . Prior to its public release, our internal version of OpenVoice was used tens of millions of times by users worldwide between May and October 2023, serving as the backend of MyShell.ai.
1 Introduction
Instant voice cloning (IVC) in text-to-speech (TTS) synthesis means the TTS model can clone the voice of any reference speaker given a short audio sample without additional training on the reference speaker. It is also referred to as Zero-shot TTS. IVC enables the users to flexibly customize the generated voice and exhibits tremendous value in a wide variety of real-world applications, such as media content creation, customized chatbots, and multi-modal interaction between humans and computers or large language models.
An abundant of previous work has been done in IVC. Examples of auto-regressive approaches include VALLE [16] and XTTS [3], which extract the acoustic tokens or speaker embedding from the reference audio as a condition for the auto-regressive model. Then the auto-regressive model sequentially generate acoustic tokens, which are then decoded to raw audio waveform. While these methods can clone the tone color, they do not allow users to flexibly manipulate other important style parameters such as emotion, accent, rhythm, pauses and intonation. Also, auto-regressive models are relatively computationally expensive and has relatively slow inference speed. Examples of non-autoregressive approach include YourTTS [2] and the recently developed Voicebox [8], which demonstrate significantly faster inference speed but are still unable to provide flexible control over style parameters besides tone color. Another common disadvantage of the existing methods is that they typically require a huge MSML dataset in order to achieve cross-lingual voice clone. Such combinatorial data requirement can limit their flexibility to include new languages. In addition, since the voice cloning research [8, 16] by tech giants are mostly closed-source, there is not a convenient way for the research community to step on their shoulders and push the field forward.
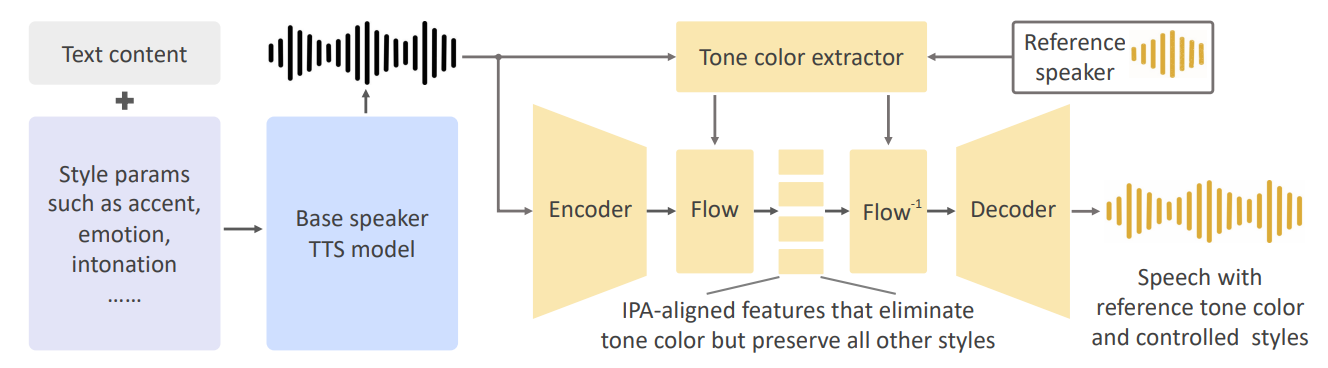
We present OpenVoice, a flexible instant voice cloning approach targeted at the following key problems in the field:
• In addition to cloning the tone color, how to have flexible control of other important style parameters such as emotion, accent, rhythm, pauses and intonation? These features are crucial for generating in-context natural speech and conversations, rather than monotonously narrating the input text. Previous approaches [2, 3, 16] can only clone the monotonous tone color and style from the reference speaker but do not allow flexible manipulation of styles.
• How to enable zero-shot cross-lingual voice cloning in a simple way. We put forward two aspects of zero-shot capabilities that are important but not solved by previous studies:
– If the language of the reference speaker is not presented in the MSML dataset, can the model clone their voice?
– If the language of the generated speech is not presented in the MSML dataset, can the model clone the reference voice and generate speech in that language?
In previous studies [18, 8], the language of the reference speaker and the generated language by the model should both exist in great quantity in the MSML dataset. But what if neither of them exist?
• How to realize super-fast speed real-time inference without downgrading the quality, which is crucial for massive commercial production environment.
To address the first two problems, OpenVoice is designed to decouple the components in a voice as much as possible. The generation of language, tone color, and other important voice features are made independent of each other, enabling flexible manipulation over individual voice styles and language types. This is achieved without labeling any voice style in the MSML training set. We would like to clarify that the zero-shot cross-lingual task in this study is different from that in VALLE-X [18]. In VALLE-X, data for all languages need to be included in the MSML training set, and the model cannot generalize to an unseen language outside the MSML training set. By comparison, OpenVoice is designed to generalize to completely unseen languages outside the MSML training set. The third problem is addressed by default, since the decoupled structure reduces requirement on model size and computational complexity. We do not require a large model to learn everything. Also, we avoid auto-regressive or diffusion components to speed up the inference.
Our internal version of OpenVoice before this public release has been used tens of millions of times by users worldwide between May and October 2023. It powers the instant voice cloning backend of MyShell.ai and has witnessed several hundredfold user growth on this platform. To facilitate the research progress in the field, we explain the technology in great details and make the source code with model weights publicly available.
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
2 We use the term MSML dataset to denote a speech dataset with multiple languages, and each language has a vast amount of speakers. It is a typical requirement for training cross-lingual instant voice cloning models.
3 https://github.com/myshell-ai/OpenVoice
4 https://research.myshell.ai/open-voice